Dan Gordon (University of Haifa), Rachel Gordon (Technion – Israel Institute of Technology), Eli Turkel (Tel Aviv University)
We consider the Helmholtz equation in 3D: 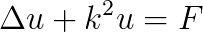 , where
, where 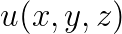 is the displacement at
is the displacement at 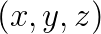 ,
, 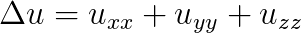 and
and 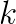 is the wave number. This equation has applications in many fields, such as acoustics and electromagnetism. In geophysics, methods of full wave inversion reconstruct the structure of some volume of the earth from data received by many sensors recording the reflection of sound waves. The frequency domain approach to this reconstruction requires the repeated solution of the Helmholtz equation, in which the RHS function
is the wave number. This equation has applications in many fields, such as acoustics and electromagnetism. In geophysics, methods of full wave inversion reconstruct the structure of some volume of the earth from data received by many sensors recording the reflection of sound waves. The frequency domain approach to this reconstruction requires the repeated solution of the Helmholtz equation, in which the RHS function 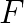 represents an impact source, so it has a small finite support.
represents an impact source, so it has a small finite support.
Due to dispersion errors (also known as the pollution effect), it is well known that problems with wave propagation are solved more efficiently by using high order accurate methods. In addition to high order accuracy, it is also useful to consider only compact stencils (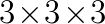 in 3D). This has several advantages. Foremost, is that no non-physical boundary conditions need be considered. In addition this reduces the bandwidth of the matrix to be inverted. Another practical advantage is that huge 3D domains require parallel solvers, and compact schemes lend themselves more easily to parallel domain decomposition techniques, such as the CARP-CG algorithm [2] used in this work.
in 3D). This has several advantages. Foremost, is that no non-physical boundary conditions need be considered. In addition this reduces the bandwidth of the matrix to be inverted. Another practical advantage is that huge 3D domains require parallel solvers, and compact schemes lend themselves more easily to parallel domain decomposition techniques, such as the CARP-CG algorithm [2] used in this work.
The main difficulty in applying a compact high order finite difference scheme to solve the Helmholtz equation on a geophysical problem is that large geophysical domains consist of different types of materials with different acoustic properties, i.e., the wave number varies within the domain. In this work we use the compact 6th order scheme of [4], which was developed for variable and shown to be far superior to lower order schemes.
However, high order finite difference schemes are not enough for correctly simulating the wave equation. The numerical solution is carried out in a finite domain, so in order to simulate an infinite domain, we need to impose so-called absorbing boundary conditions (ABCs) that will inhibit reflections from the boundaries. One of the first ABCs was formulated by Engquist and Majda. An equivalent BC was later formulated by Higdon [3]. For spherical domains, a series of absorbing boundary conditions was developed in [1]. We have developed several compact high order schemes based on these ABCs, including a novel approach for improved accuracy at the corners.
In order to evaluate the various ABCs, we ran experiments on a domain with a constant and a known analytic solution. The source was simulated by a function of the type 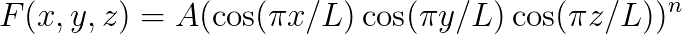 for
for 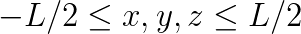 and zero elsewhere.
and zero elsewhere. 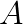 is the amplitude,
is the amplitude,  , and
, and 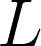 determines the size of the support. Experiments were ran with various frequencies.
determines the size of the support. Experiments were ran with various frequencies.
It is well known that for constant , the analytic solution is obtained by a convolution of and 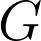 , where is the Green's function for 3D. The convolution integral was calculated numerically and compared with the solutions obtained by various ABCs.
, where is the Green's function for 3D. The convolution integral was calculated numerically and compared with the solutions obtained by various ABCs.
In order to determine the quality of the ABCs in absolute terms, the ABC results were compared with the solution obtained when Dirichlet boundary conditions were imposed on the exterior boundaries. The values on the boundaries were determined by the numerical convolution of and . Obviously, no ABC can do better than such a Dirichlet BC. We conclude with a geophysical application.
References
[1] Bayliss, Gunzburger // Turkel. SIAM J. Appl. Math., 1982.
[2] Gordon // Gordon. Paral. Comput., 2010.
[3] Higdon. Math. of Comput., 1987.
[4] Turkel, Gordon, Gordon // Tsynkov. J. Comput. Physics, 2013.
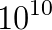 Pa s), which may occur over a wide range of length scales ranging from meters to kilometers.
Pa s), which may occur over a wide range of length scales ranging from meters to kilometers. in all time steps, a high level of temporal accuracy can only be achieved by choosing overall small time step sizes. However, this leads to a tremendous increase in computational time, especially when such small time step sizes are not necessary throughout the entire simulation in order to maintain the desired level of accuracy. By choosing the time step sizes
in all time steps, a high level of temporal accuracy can only be achieved by choosing overall small time step sizes. However, this leads to a tremendous increase in computational time, especially when such small time step sizes are not necessary throughout the entire simulation in order to maintain the desired level of accuracy. By choosing the time step sizes 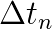 adaptively and individually for each time step
adaptively and individually for each time step 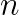 , the local discretization error of the applied time integration scheme can be limited to a user-given bound and, thus, one can achieve the desired level of accuracy by simultaneously limiting the computational costs. Therefore, we combine established error estimation procedures in the structure and fluid field (see e.g. [Zienkiewicz et al., Earthquake Engng. Struct. Dyn. (20), pp. 871-887, 1991], [Gresho et al., SIAM J. Sci. Comput. (30), pp. 2018-s2054, 2008], [Kay et al., SIAM J. Sci. Comput. (32), pp. 111-128, 2010]) to build an adaptive time stepping algorithm for fluid-structure interaction problems. This algorithm is integrated into the monolithic solver framework proposed in [Mayr et al., 2014]. By controlling the local temporal discretization error in the structure and fluid field, an optimal time step size can be selected that satisfies the accuracy demands in both fields.
, the local discretization error of the applied time integration scheme can be limited to a user-given bound and, thus, one can achieve the desired level of accuracy by simultaneously limiting the computational costs. Therefore, we combine established error estimation procedures in the structure and fluid field (see e.g. [Zienkiewicz et al., Earthquake Engng. Struct. Dyn. (20), pp. 871-887, 1991], [Gresho et al., SIAM J. Sci. Comput. (30), pp. 2018-s2054, 2008], [Kay et al., SIAM J. Sci. Comput. (32), pp. 111-128, 2010]) to build an adaptive time stepping algorithm for fluid-structure interaction problems. This algorithm is integrated into the monolithic solver framework proposed in [Mayr et al., 2014]. By controlling the local temporal discretization error in the structure and fluid field, an optimal time step size can be selected that satisfies the accuracy demands in both fields.  -step formulation of BICGSTAB (CA-BICGSTAB for short) as a high performance, distributed-memory bottom solver for geometric multigrid. This is the first time an
-step formulation of BICGSTAB (CA-BICGSTAB for short) as a high performance, distributed-memory bottom solver for geometric multigrid. This is the first time an 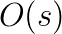 fewer global reductions over a fixed number of iterations at the cost of a constant factor of additional floating point operations and peer-to-peer messages. Furthermore, while increasing
fewer global reductions over a fixed number of iterations at the cost of a constant factor of additional floating point operations and peer-to-peer messages. Furthermore, while increasing  on synthetic problems and up to
on synthetic problems and up to 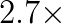 in real applications with parameter
in real applications with parameter 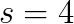 . This improvement resulted in up to a
. This improvement resulted in up to a 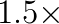 speedup in the overall geometric multigrid solve in real applications.
speedup in the overall geometric multigrid solve in real applications. -correction" that represents the incremental influence of the fine grid on the coarse grid. This influence is robust to long-wavelength perturbations to the problem, allowing reuse between successive nonlinear iterations, time steps, or solves. For non-smooth problems such as brittle failure and contact, this permits fine grids to be skipped in regions away from the active nonlinearity. This technique provides benefits similar to adaptive mesh refinement, but is more general because the problem can have arbitrary fine-scale microstructure. We introduce the new method and present numerical results in the context of long-term lithosphere applications.
-correction" that represents the incremental influence of the fine grid on the coarse grid. This influence is robust to long-wavelength perturbations to the problem, allowing reuse between successive nonlinear iterations, time steps, or solves. For non-smooth problems such as brittle failure and contact, this permits fine grids to be skipped in regions away from the active nonlinearity. This technique provides benefits similar to adaptive mesh refinement, but is more general because the problem can have arbitrary fine-scale microstructure. We introduce the new method and present numerical results in the context of long-term lithosphere applications.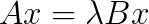 , where
, where 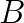 are Hermitian, and the pair is definite, i.e., there exist constants
are Hermitian, and the pair is definite, i.e., there exist constants 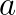 and
and 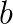 such that
such that 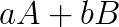 is positive definite.
is positive definite.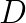 (this step is not necessary) and the Cholesky factorization of
(this step is not necessary) and the Cholesky factorization of 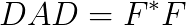 and
and 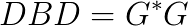 , the problem can be seen as the computation of the generalized singular value decomposition SVD of the Cholesky factors
, the problem can be seen as the computation of the generalized singular value decomposition SVD of the Cholesky factors 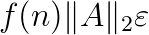 , where
, where 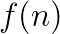 is some slowly growing function of the matrix order
is some slowly growing function of the matrix order 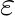 is the machine precision. Thus, eigenvalues of larger modulus are computed with high relative accuracy, while the smaller ones may not be relatively accurate at all. On the other hand, we can also reduce our matrix to tridiagonal skew-symmetric matrix and compute the eigenvalues by the bidiagonal QR method (without shifts) with high relative accuracy. Although Pietzsch method has the merit of accuracy, its disadvantage, as with other Jacobi-like methods, is speed, since algorithms of this class are known to be quite slow despite their quadratic convergence.
is the machine precision. Thus, eigenvalues of larger modulus are computed with high relative accuracy, while the smaller ones may not be relatively accurate at all. On the other hand, we can also reduce our matrix to tridiagonal skew-symmetric matrix and compute the eigenvalues by the bidiagonal QR method (without shifts) with high relative accuracy. Although Pietzsch method has the merit of accuracy, its disadvantage, as with other Jacobi-like methods, is speed, since algorithms of this class are known to be quite slow despite their quadratic convergence. , where
, where 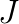 is a block diagonal matrix consisting of
is a block diagonal matrix consisting of 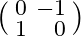 blocks. In the second part, we orthogonalize columns of matrix
blocks. In the second part, we orthogonalize columns of matrix 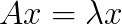 , is an important problem that has applications in quantum chemistry, electronic structure calculation and statistical calculation. In this study, we deal with the problem of computing all the eigenvalues and eigenvectors of a symmetric matrix
, is an important problem that has applications in quantum chemistry, electronic structure calculation and statistical calculation. In this study, we deal with the problem of computing all the eigenvalues and eigenvectors of a symmetric matrix 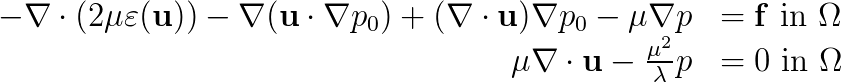 where the coefficients
where the coefficients 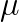 ,
, 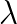 are the Lamé coefficients,
are the Lamé coefficients, 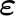 is the strain tensor,
is the strain tensor, 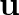 is the displacement vector,
is the displacement vector, 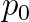 is the so-called pre-stress,
is the so-called pre-stress,  is a body force and
is a body force and 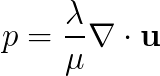 is the so-called kinematic pressure, introduced in order to be able to simulate fully incompressible materials, for which
is the so-called kinematic pressure, introduced in order to be able to simulate fully incompressible materials, for which 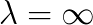 .
.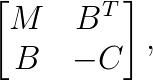 where the pivot block
where the pivot block 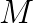 is nonsymmetric.
is nonsymmetric.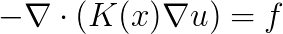 on bounded domains
on bounded domains 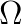 .
. 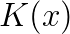 . It is developed for massively parallel supercomputers with a low amount of main memory per core. Due to a greedy heuristic used for the coarsening the method has a low memory footprint and allows for scalable subsurface flow simulations with up to 150 billion unknowns on nearly 300 thousand cores.
. It is developed for massively parallel supercomputers with a low amount of main memory per core. Due to a greedy heuristic used for the coarsening the method has a low memory footprint and allows for scalable subsurface flow simulations with up to 150 billion unknowns on nearly 300 thousand cores.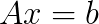 , where
, where 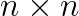 matrix,
matrix, 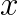 and
and 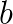 are solution and right-hand side vectors of order
are solution and right-hand side vectors of order 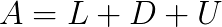 , where
, where 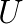 and
and 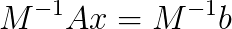 , where
, where 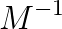 means a preconditioner matrix.
means a preconditioner matrix. 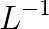 and
and 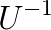 as splits of coefficient matrix
as splits of coefficient matrix 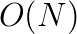 ) methods for graph analytics. In this talk we will focus on two algorithms: estimating subgraph centralities (measure for the importance of a node), and spectrograms (density of eigenvalues) of the adjacency matrix of the graph. On one hand we discuss the underlaying mathematical models relaying on matrix trace estimation techniques. On the other hand we discuss the exhibited parallelism on multiple levels in order to attain good parallel efficiency on a large number of processes. To that end we explore the scalability of the proposed algorithms with benchmarks on huge datasets, e.g. the graph of the European street network containing 51 million nodes and 108 million non-zeros. Due to the iterative behavior of the methods, a very good estimate can be computed in a matter of seconds.
) methods for graph analytics. In this talk we will focus on two algorithms: estimating subgraph centralities (measure for the importance of a node), and spectrograms (density of eigenvalues) of the adjacency matrix of the graph. On one hand we discuss the underlaying mathematical models relaying on matrix trace estimation techniques. On the other hand we discuss the exhibited parallelism on multiple levels in order to attain good parallel efficiency on a large number of processes. To that end we explore the scalability of the proposed algorithms with benchmarks on huge datasets, e.g. the graph of the European street network containing 51 million nodes and 108 million non-zeros. Due to the iterative behavior of the methods, a very good estimate can be computed in a matter of seconds. where
where 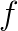 is a quadratic function of the form
is a quadratic function of the form 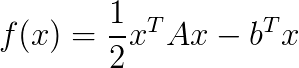 and
and 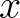 satisfying zero or more prescribed constraints of any of the following forms
\begin{align}
B_Ex &= c_E,
satisfying zero or more prescribed constraints of any of the following forms
\begin{align}
B_Ex &= c_E,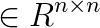 is the symmetric positive semidefinite Hessian matrix,
is the symmetric positive semidefinite Hessian matrix,
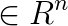 is the right hand side vector,
is the right hand side vector,
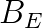
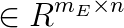 is the equality constraint matrix,
is the equality constraint matrix,
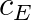
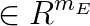 is the equality constraint right hand side vector,
is the equality constraint right hand side vector,
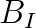
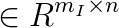 is the inequality constraint matrix,
is the inequality constraint matrix,
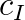
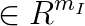 is the inequality constraint right hand side vector,
is the inequality constraint right hand side vector,
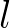
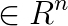 is the lower bound vector,
and
is the lower bound vector,
and 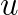
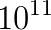 unknowns if the horizontal resolution is increased to around 1 kilometer in a global model run and weather forecasts can only be produced at operational time scales at this resolution if the PDE can be solved in a fraction of a second. Only solvers which are algorithmically scalable and can be efficiently parallelised on
unknowns if the horizontal resolution is increased to around 1 kilometer in a global model run and weather forecasts can only be produced at operational time scales at this resolution if the PDE can be solved in a fraction of a second. Only solvers which are algorithmically scalable and can be efficiently parallelised on 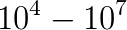 processor cores can deliver this performance. As the equation is solved in a thin spherical shell representing the earth's atmosphere, the solver has to be able to handle very strong vertical anisotropies; equations with a similar structure arise in many other areas in the earth sciences such as global ocean models, subsurface flow simulations and ice sheet models.
processor cores can deliver this performance. As the equation is solved in a thin spherical shell representing the earth's atmosphere, the solver has to be able to handle very strong vertical anisotropies; equations with a similar structure arise in many other areas in the earth sciences such as global ocean models, subsurface flow simulations and ice sheet models.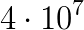 individual cores) of the Titan supercomputer (#2 www.top500.org, Nov 2013) and the EMERALD cluster. The largest system, we studied has
individual cores) of the Titan supercomputer (#2 www.top500.org, Nov 2013) and the EMERALD cluster. The largest system, we studied has 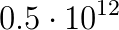 unknowns and can be solved in one second with our matrix-free tensor-product multigrid solver on Titan. On this machine our implementation achieves a peak performance of up to 0.8 petaFLOPs per second and it can utilise between 25% and 50% of the global memory bandwidth, which is a sizeable fraction for a memory bound application.
unknowns and can be solved in one second with our matrix-free tensor-product multigrid solver on Titan. On this machine our implementation achieves a peak performance of up to 0.8 petaFLOPs per second and it can utilise between 25% and 50% of the global memory bandwidth, which is a sizeable fraction for a memory bound application.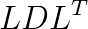 factorization of F-type saddle point matrices. IMA Journal of Numerical Analysis, 29(1), 208-234, 2009.
factorization of F-type saddle point matrices. IMA Journal of Numerical Analysis, 29(1), 208-234, 2009.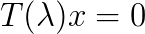 , where
, where 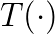 is a matrix function analytic in a given region
is a matrix function analytic in a given region 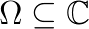 . We are interested in computing a few eigenvalues
. We are interested in computing a few eigenvalues 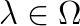 and their corresponding eigenvectors
and their corresponding eigenvectors 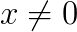 of large-scale problems by means of iterative methods.
of large-scale problems by means of iterative methods.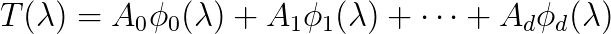 , where
, where  are square matrices (typically sparse) and
are square matrices (typically sparse) and  are scalar functions analytic in
are scalar functions analytic in 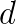 and hence the
and hence the 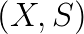 , which generalize invariant subspaces to the nonlinear case. An invariant pair satisfies
, which generalize invariant subspaces to the nonlinear case. An invariant pair satisfies 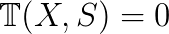 with
with 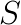 is an eigenvalue of the nonlinear eigenproblem.
is an eigenvalue of the nonlinear eigenproblem.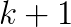 when the
when the 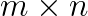 (
( ) matrices. In problems concerning scientific applications such as data search and rank-
) matrices. In problems concerning scientific applications such as data search and rank- ) approximation,
) approximation,  ) singular pairs, i.e. singular values
) singular pairs, i.e. singular values 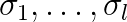 (
(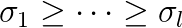 ) and the corresponding singular vectors, are often required. For a large-scale sparse matrix, it is difficult to perform SVD directly with respect to execution time. In this case, the target matrix is transformed into a small matrix whose singular values are approximated well to those of the original matrix as the preprocessing is performed by using Krylov subspace methods.
) and the corresponding singular vectors, are often required. For a large-scale sparse matrix, it is difficult to perform SVD directly with respect to execution time. In this case, the target matrix is transformed into a small matrix whose singular values are approximated well to those of the original matrix as the preprocessing is performed by using Krylov subspace methods. 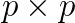 bidiagonal matrix (
bidiagonal matrix (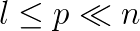 ) is replaced with an eigenproblem for a symmetric tridiagonal matrix in terms of a
) is replaced with an eigenproblem for a symmetric tridiagonal matrix in terms of a 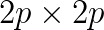 extended matrix. From the
extended matrix. From the 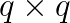 approximate block bidiagonal matrix (
approximate block bidiagonal matrix (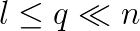 ). As with the GKL algorithm, the
). As with the GKL algorithm, the 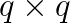 bidiagonal matrix by the Murata method, and computing the
bidiagonal matrix by the Murata method, and computing the 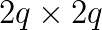 extended matrix. In our approach, we compute the
extended matrix. In our approach, we compute the 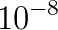 . Without an efficient, scalable and parallel method one cannot expect to simulate stellar processes with the necessary resolution in time or space.
. Without an efficient, scalable and parallel method one cannot expect to simulate stellar processes with the necessary resolution in time or space. 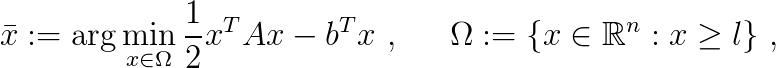 where
where 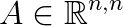 is a symmetric positive semidefinite matrix,
is a symmetric positive semidefinite matrix, 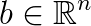 is a right-hand side vector, and
is a right-hand side vector, and 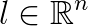 is a vector of bound constraints. To include the possibility that not all the components of
is a vector of bound constraints. To include the possibility that not all the components of 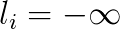 .
In this paper, we propose a modification of recently developed Modified Proportioning with Reduced Gradient Projection (MPRGP) method. This algorithm combines the conjugate gradient steps with the reduced gradient projection steps. Optimality of MPRGP was recently demonstrated on the solution of a class of problems with spectrum of
.
In this paper, we propose a modification of recently developed Modified Proportioning with Reduced Gradient Projection (MPRGP) method. This algorithm combines the conjugate gradient steps with the reduced gradient projection steps. Optimality of MPRGP was recently demonstrated on the solution of a class of problems with spectrum of 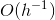 which is already a much better conditioned system than
which is already a much better conditioned system than 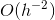 condition number of the global problem. However, the Schur complement matrix itself is not available explicitly, consequently, some of the approaches such as incomplete factorization that are easily applicable when solving the global linear system is not directly applicable when solving the Shur complement system. Nevertheless, countless preconditioners have been proposed for the Schur complement system.
condition number of the global problem. However, the Schur complement matrix itself is not available explicitly, consequently, some of the approaches such as incomplete factorization that are easily applicable when solving the global linear system is not directly applicable when solving the Shur complement system. Nevertheless, countless preconditioners have been proposed for the Schur complement system.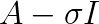 . Even for positive definite matrices
. Even for positive definite matrices 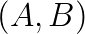 by taking account of manycore processors. Here,
by taking account of manycore processors. Here, 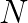 -by-
-by-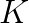 , and
, and 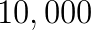 and
and 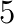 . Thus the acceleration of the solver of the GEPs of such narrow band matrices is important.
. Thus the acceleration of the solver of the GEPs of such narrow band matrices is important.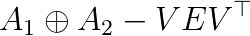 and
and 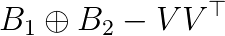 respectively, where
respectively, where 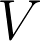 is an
is an 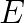 is an
is an 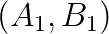 and
and 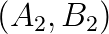 , (3) computing the eigenpairs from the solutions of the sub GEPs, V and E. It is noteworthy that both A and B are expressed with the same matrix V. Alternative decomposition
, (3) computing the eigenpairs from the solutions of the sub GEPs, V and E. It is noteworthy that both A and B are expressed with the same matrix V. Alternative decomposition 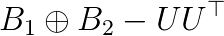 , where
, where 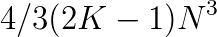 . It is less than the conventional methods when
. It is less than the conventional methods when 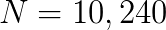 ,
, 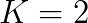 ) of the proposed method is 53.9 seconds which is 18.5 times faster than the conventional one. Secondly, we evaluate parallel version, which is modified to offload large dimensional matrix multiplications to Xeon Phi from the CPU-only version. The execution time of the proposed method is 34.7 seconds and it is 29.3 times faster than the conventional method. The value on a Xeon Phi represents speed-up of 1.55 times in comparison to the CPU-only version. In the experiment, the matrix data for matrix multiplications are transferred between the CPU and the coprocessor redundantly. Thus, the acceleration rate of the proposed method can be better. The results imply that the proposed method is faster than the conventional method on both ordinary CPU and manycore processor. In addition, the proposed method shows the higher acceleration rate on many core processors.
) of the proposed method is 53.9 seconds which is 18.5 times faster than the conventional one. Secondly, we evaluate parallel version, which is modified to offload large dimensional matrix multiplications to Xeon Phi from the CPU-only version. The execution time of the proposed method is 34.7 seconds and it is 29.3 times faster than the conventional method. The value on a Xeon Phi represents speed-up of 1.55 times in comparison to the CPU-only version. In the experiment, the matrix data for matrix multiplications are transferred between the CPU and the coprocessor redundantly. Thus, the acceleration rate of the proposed method can be better. The results imply that the proposed method is faster than the conventional method on both ordinary CPU and manycore processor. In addition, the proposed method shows the higher acceleration rate on many core processors. . Each sequence,
. Each sequence, 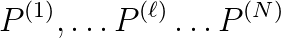 , groups together eigenproblems with increasing
outer-iteration index
, groups together eigenproblems with increasing
outer-iteration index 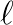 .
. 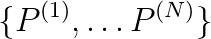 is said to be a “sequence” if the solution of the
is said to be a “sequence” if the solution of the
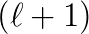 -th eigenproblem. For instance at
the beginning of each DFT cycle an initial function
-th eigenproblem. For instance at
the beginning of each DFT cycle an initial function
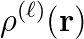 determines the initialization of the
determines the initialization of the
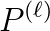 eigenpairs
are then use to compute a new
eigenpairs
are then use to compute a new 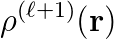 which, in
turn, leads to the initialization of a new eigenvalue problem
which, in
turn, leads to the initialization of a new eigenvalue problem
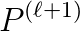 . In addition to be part of a sequence, successive
eigenproblems might possess a certain degree of correlation connecting
their respective eigenpairs. In DFT sequences, correlation becomes
manifest in the way eigenvectors of successive eigenproblems become
progressively more collinear to each other as the
. In addition to be part of a sequence, successive
eigenproblems might possess a certain degree of correlation connecting
their respective eigenpairs. In DFT sequences, correlation becomes
manifest in the way eigenvectors of successive eigenproblems become
progressively more collinear to each other as the 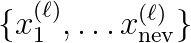 , as well as very reliable estimates, namely
, as well as very reliable estimates, namely
![[\lambda_1^{(\ell)},\ \lambda_{\rm nev}^{(\ell)}]](../img/eqn/5B5Clambda_15E7B285Cell297D2C5C205Clambda_7B5Crm20nev7D5E7B285Cell297D5D.png) , for the limits of
the eigenspectrum interval
, for the limits of
the eigenspectrum interval ![[a,\ b]](../img/eqn/5Ba2C5C20b5D.png) to be filtered in. In addition
the degree of the polynomial filter is adjusted so as to be minimal
with respect to the required tolerance for the eigenpairs
residual. This result is achieved by exploiting the dependence each
eigenpair residual have with respect to its convergence ratio as
determined by the rescaled Chebyshev polynomial and its
degree. The solver is complemented with an efficient mechanism which locks and
deflates the converged eigenpairs.
to be filtered in. In addition
the degree of the polynomial filter is adjusted so as to be minimal
with respect to the required tolerance for the eigenpairs
residual. This result is achieved by exploiting the dependence each
eigenpair residual have with respect to its convergence ratio as
determined by the rescaled Chebyshev polynomial and its
degree. The solver is complemented with an efficient mechanism which locks and
deflates the converged eigenpairs.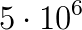 .
. 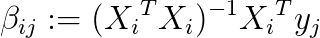 , where
, where
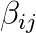 determines the relation between a genetic marker
determines the relation between a genetic marker 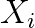 and a trait
and a trait 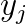 .
In GWAS, the above equation has to be solved for the cross product of
.
In GWAS, the above equation has to be solved for the cross product of 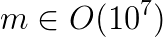 matrices
matrices 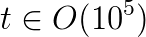 vectors
vectors 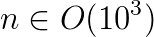 ,
resulting in the computation of the order of peta-floating point operations (petaflops)
over terabytes of data.
The proposed solvers deal with the high computational requirements of GWAS
efficiently, reducing considerably the required time to solution when
compared to existing solvers.
,
resulting in the computation of the order of peta-floating point operations (petaflops)
over terabytes of data.
The proposed solvers deal with the high computational requirements of GWAS
efficiently, reducing considerably the required time to solution when
compared to existing solvers. Km): On the one hand the execution time is prohibitive and, on the other hand, the amount of memory required to tackle such problem is usually not available in a single node. Both problems are related to the number of cells describing the terrain.
Km): On the one hand the execution time is prohibitive and, on the other hand, the amount of memory required to tackle such problem is usually not available in a single node. Both problems are related to the number of cells describing the terrain.